COBOL技術者は絶滅危惧種→再び脚...
2024.01.09
ビジネスジャーナル









内定辞退率を予測するためのプロファイリングは、学生を採用する企業には有用だが、応募する側の学生にとってはショッキングだっただろう。まさか自分のウェブ閲覧履歴が内定辞退率の予測に使われ、内定が取り消される可能性があったとは思わなかったからだ。
セグメントに基づくAIの確率的評価は、憲法13条の個人の尊重と矛盾しうる側面もある。さらにディープラーニングのような複雑な学習方法を用いると、AIの判断は人間には理解できなくなるというブラックボックス問題が生じる。
AIに低い評価をされた人になぜそうなったのかの理由が説明されず、個人が再挑戦の機会を失って社会的に排除され続けるという事態も生じるかもしれない。いわゆる「バーチャルスラム」だ。憲法の精神からいって、これは避けなければならない。
ウェブサイト上のいわゆるクッキー情報を使ったプロファイリングのみならず、今後はメタバースが広がりヘッドギアをつけてVR(仮想現実)空間に没入するようになれば、アイトラッキングといった視線分析や脳波測定まで行えるようになるだろう。政治からマーケティングまで、今や幅広い領域で人々の「認知」が標的となり、その手法も日増しに高度化している。
――AIを用いたプロファイリングについては、「ChatGPT」のような生成AIでも問題になるのでしょうか。
プロファイリングと呼ぶかどうかはわからないが、似たような問題は起こるだろう。運営会社のオープンAIが3月中旬に公開した大規模言語モデル「GPT-4」は、AIが学習したデータの規模や中身を明らかにしていない。
彼らがどのようなデータを、どれぐらい集め、どのような解析を行っているかがわからなければ、GPT-4の回答に入っているバイアスの中身もわからない。GPT-4の回答次第で個人の認知過程が歪むということは十分にありうる。
生成AIについては中国が自前の開発を進めているとも報じられているが、中国のような一党体制下では、学習データやアルゴリズムが調整され、国が回答してほしい内容を生成AIが回答するということになるかもしれない。そうした国家間の開発競争が繰り広げられる中で、はたしてオープンAIは「中立的」と言えるのか。
フェイクニュースを排除したり、誹謗中傷を含む回答をしたりしないということは重要だが、何がフェイクで何が誹謗中傷に当たるかの判断には、一定の価値判断を伴う。
そもそも、フェイクニュース対策を講じたり、誹謗中傷対策を講じたりするということ自体が一定の価値判断に基づいている。生成AIのポリシーやアルゴリズム次第で、言論空間が大きく歪められ、主権国家がつぶれることもあるかもしれない。限界はあるとしても、運営の透明性を確保することは極めて重要だ。
――AIの開発・運用の透明性を高め、その監視機能を強めるには、どうすればいいのでしょうか?
第三者による監督委員会を設けることも一案だろう。フェイスブック(現メタ)では、世界各国の専門家で構成される監督委員会が、コンテンツ削除に関するメタの判断が同社のポリシー、価値観、人権への取り組みなどに従ったものであったかどうかを審査している。
今後は、レコメンデーションや自動削除のためのAI・アルゴリズムの妥当性や倫理性も監督委員会が審査すべきだという意見もある。チャットGPTのような生成AIでも、ポリシーやアルゴリズムの妥当性を審査する仕組みが必要になるだろう。
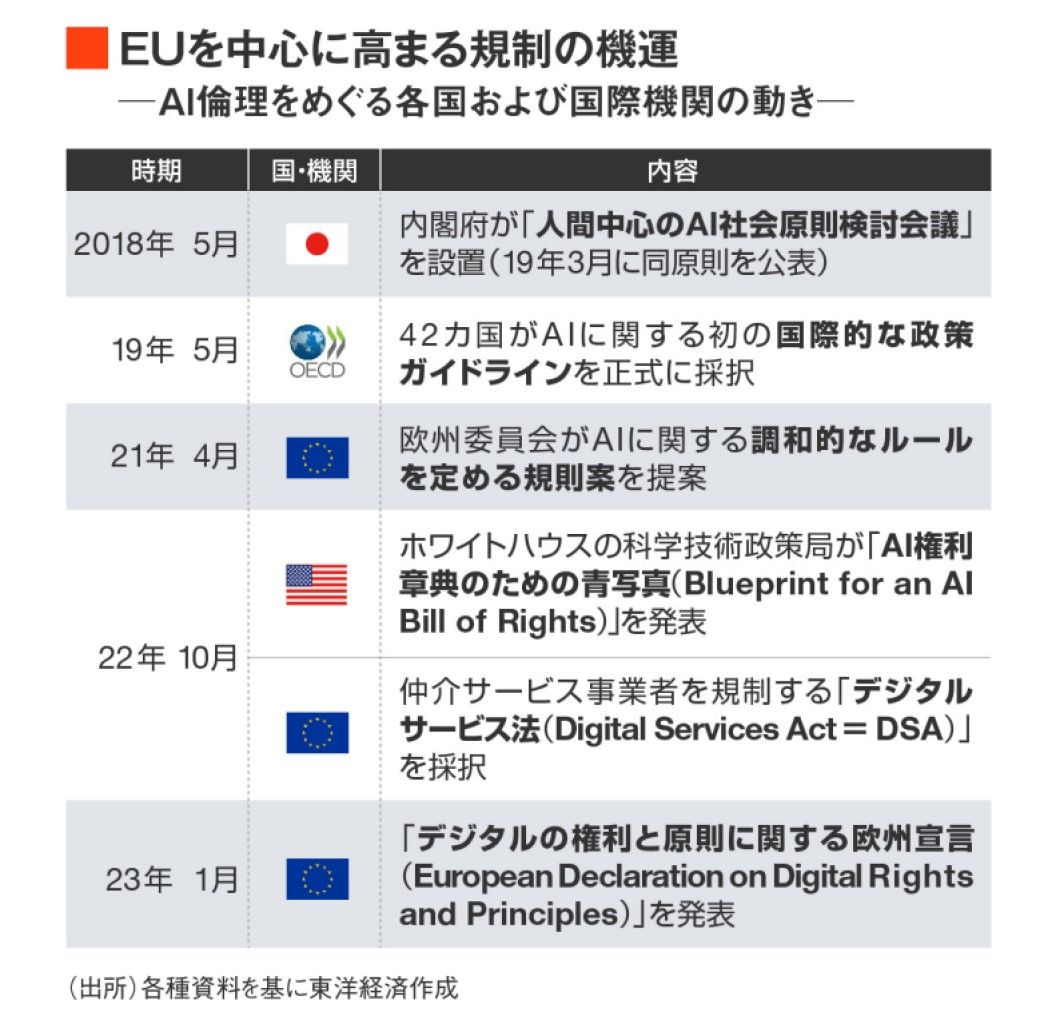
一方で、法的な枠組みも必要になる。EU(欧州連合)では2021年4月に欧州委員会が、AIに関する規則案を発表している。2024年に完全施行される予定で、人々の行動を歪めることを禁じたり、生成AIのようなチャットボットに対する透明性を義務づけることを求めたりしている。違反した企業は、最大で3000万ユーロ(約42億円)か、全世界における売上高6%のうちどちらか高い金額を制裁金として支払わなければならない。